
背景
Webアプリケーション開発をする上で、HTTPは重要な概念である。
という雰囲気を日々ひしひしと感じています。知らなくても別にコーディングにそれほど支障がでない、という気もしますが、何か重要なものを抜け落としている気がしてならない。
ということで調べてみた。「HTMLドキュメントのようなリソースを取ってくるための規約」(mozilla “An overview of HTTP”)らしい。
まだ抜け落としている気がしてならない。うん、ちゃんと調べてみよう。
概要

HTTPとは、クライアント – サーバー間でデータをやり取りするための規約です。私たちは、Youtubeで動画を見る時、adidasのオンラインショップで靴を選ぶ時、webブラウザを通して、HTML文書や動画、画像をデータサーバーに要求し、送られてきたそれらをwebブラウザで組み立て、表示しています。
クライアントとサーバーは個々のメッセージを交換することによって、通信します。Webブラウザが送ったメッセージは、リクエスト (request) と呼ばれ、サーバーが送った返答は、レスポンス (response) と呼ばれます
mdn web docs, “An overview of HTTP”, https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview#http_messages
今では当たり前のその仕組みですが、その歴史は思ったよりも深くはありません。
1990年、Tim Barners-Leeはインターネット上でhypertextシステムをbuildした (Web)。Webは既存のTCP、IPプロトコルの上に構築され、4つのブロックから構成された。
mdn web docs “Evolution of HTTP” https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP#http3_-_http_over_quic
- hypertext文書を表現するためのテキスト形式 、HyperText Markup Language (HTML)。
- それらのドキュメントを交換するためのシンプルな規則、HyperText Transfer Protocol (HTTP)。
- それらのドキュメントを表示・編集するためのクライアント、最初のウェブブラウザをWorldWideWebと名付けた。
- ドキュメントへのアクセスを与えるサーバー、httpdの初期バージョン。
1990年なんて、つい30年前のことですが、その時に始まったと思うと、改めてネットの普及がどれだけ急速なものだったのかを実感します。これを知った時に思い出したのは大学の先生の話です。「昔は他の研究グループからデータをもらうのに、手紙を書いてフロッピーディスクを送ってもらった」
そんな時代もあったんだな、と思ったことを覚えています。
HTTPに基づいた通信の構成要素
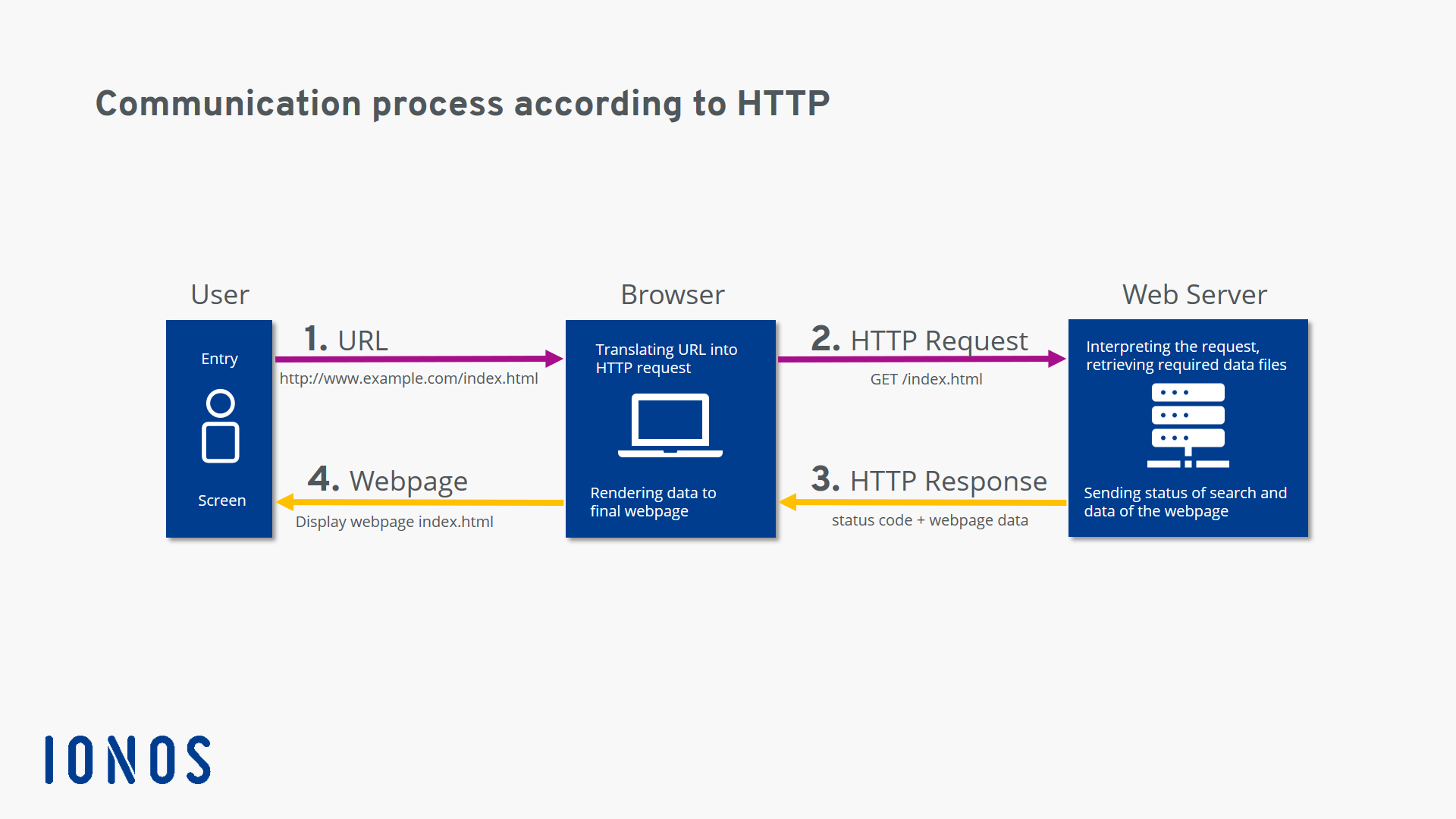
クライアント – サーバー間のやり取りを示した模式図

HTTPに基づいたシステムには、クライアントとサーバー、そして、クライアント – サーバー間でデータのやり取りを行う際、様々な操作の実行やゲートウェイとしてふるまうコンピューターがあり、これをProxy (代理人)と呼びます。HTTP Proxyは、proxy serverの一種です。[1]
それぞれについて、簡単に紹介していきます。
クライアント : ユーザーエージェント
クライアント (僕達) は知ってか知らずか、Webページを表示する時にリクエストを送っています。と言っても、僕達はURLを指定するだけで、それをユーザーエージェントがサーバーに理解できるように変換し、送信してくれます。そして、一般的にWebブラウザ(ChromeやFirefox)がこの役目を担います。
また、サーバーからリソース(HTML文書や画像等)を受け取り、Webページとしてクライアントに表示してくれるのもWebブラウザです。Webブラウザ様様です。
Webブラウザは、常にリクエストを初期化し、HTML文書やレイアウト情報 (CSS) 等を取得するために、サーバーへと送ります。
Webブラウザは、HTTPリクエストを送信してWebサーバーからリソース(HTML文書やレイアウト情報など)を取得します。
Webブラウザは、取得したリソースを解析し、完成したWebページを表示します。
Webサーバー
サーバーは、クライアント (Webブラウザ) が送信したリクエストに応じて、リソース (HTML文書や画像) を提供します。サーバーは仮想的に1台のマシンのように見えますが、実際は負担を共有した (load balancing) サーバーの集合であることがあります。[1]
load balancerは、サーバーの前に位置し、最高速度 かつ いずれのサーバーにも負荷がかからないように、クライアントからのリクエストをすべてのサーバーに送信します。また、もし、1つのサーバーがダウンしてしまった場合、load balancerは残りのオンラインサーバーに対して、リクエストを送信します。さらに、新たなサーバーがサーバーグループに加えられたとき、そのサーバーに対して、自動的にリクエストを送信します。[2]
ロードバランスの模式図

Proxy

Proxy(代理人) は、クライアントとサーバーの間で行われるリクエスト・レスポンスに対して、決められた処理を行ってくれる (セキュリティやload balance等)、コンピューターです。
- キャッシング(ブラウザのキャッシュのように、公開または非公開にすることができる)
- フィルタリング(例, アンチウィルススキャン)
- ロードバランシング
- 認証
- ロギング(履歴の保存)
先ほど話したロードバランスもProxyが行ってくれる処理の1つです。
HTTメッセージ
ユーザーがWebページを表示する流れについて、ここまでに何度か説明してきました。
最後に、Webブラウザ – サーバー間のメッセージを見ていきます。
対象は、この記事の至るところで引用させていただいているmdn web docsのAn overview of HTTPです。
firefoxの開発者ツールから、リクエストとレスポンスを見ていきます。
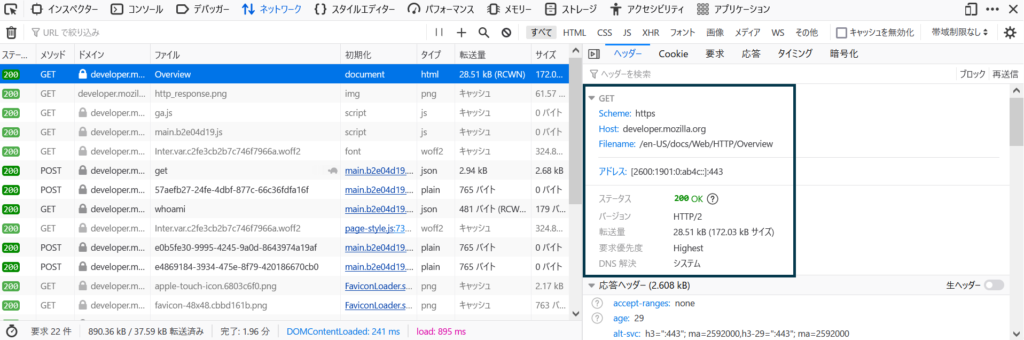
HTTP request
Get
Scheme : https
Host : developer.mozillar.org
Filename : en-US/docs/Web/HTTP/Overview
HTTP response
ステータス : 200 OK
バージョン : HTTP/2
28.51kB
要求優先度 : Highest
DNS解決 : システム
1つ1つの行が持っている意味は、以下のようになります。[3]
| 項目 | 説明 |
|---|---|
| Get | HTTPメソッドの種類 |
| スキーム | 使用しているプロトコル |
| ホスト | リクエスト先 |
| ファイル名 | 要求しているファイル |
| ステータス | リクエストの状況 |
| バージョン | HTTPプロトコルのバージョン |
| レスポンスサイズ(28.51kB) | 取得したコンテンツのサイズ |
| 要求優先度 | リクエストの優先度 高い場合、他のリクエストよりも優先的に処理される |
| DNS解決 | ホスト名をIPアドレスに変換するシステム |
今回の例ですと、developer.mozillar.orgに対して、Getのリクエストをし、無事に成功した(200)ことを示しております。
まとめ
- HTTPとは、クライアント – サーバー間でデータをやり取りするための規則
- Webブラウザは、クライアントとサーバーの間に位置し、互いのデータ 及び メッセージのやり取りを手助けする
- メッセージの中身はWebブラウザから確認することができる
参考文献
- mdn web docs, “An overview of HTTP”, https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
- NGINX, “What Is Load Balancing?”, https://www.nginx.com/resources/glossary/load-balancing/ 執筆者一部抜粋, 拙訳
- OpenAI. (2023). ChatGPT (Sep 24 version) [Large language model]. https://chat.openai.com/chat







コメント